
چگونه دادههای پرت (Outliers) را در یادگیری ماشین تشخیص دهیم؟
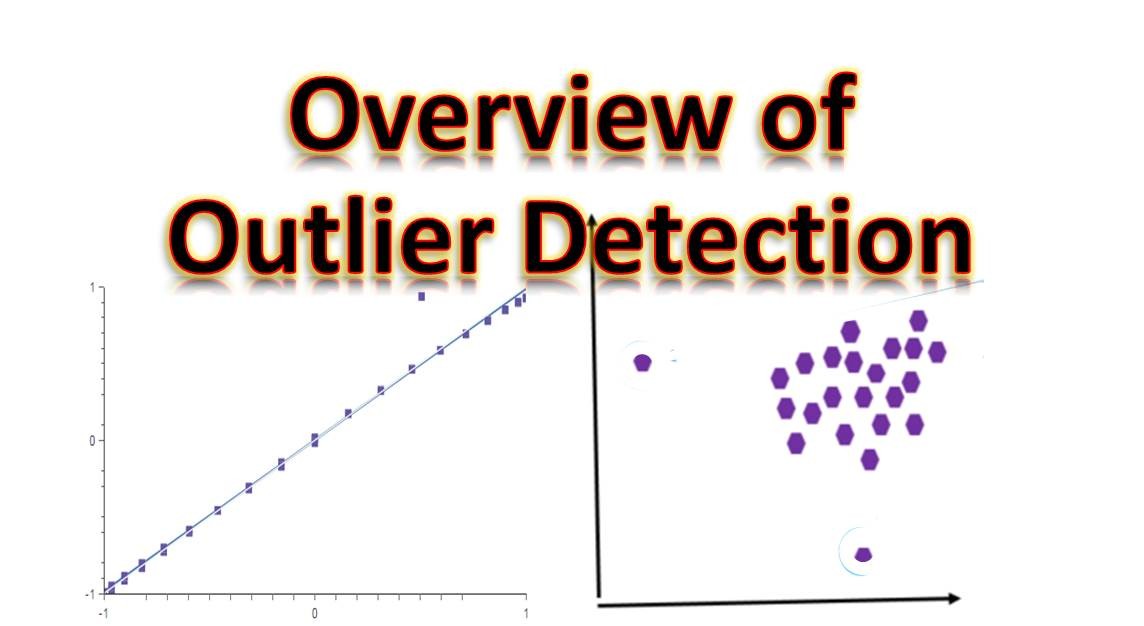
چگونه دادههای پرت (Outliers) را در یادگیری ماشین تشخیص دهیم؟
در یادگیری ماشین، دادههای پرت (Outliers) نقاط دادهای هستند که به طور قابل توجهی از سایر نقاط داده در یک مجموعه فاصله دارند. این مقاله به بررسی اصول اولیه دادههای پرت و نحوه مدیریت آنها برای حل مسائل یادگیری ماشین میپردازد.
فهرست مطالب
- دادههای پرت چیست؟
- روشهای تشخیص دادههای پرت در یادگیری ماشین
- تکنیکهای مدیریت دادههای پرت در یادگیری ماشین
- اهمیت تشخیص دادههای پرت در یادگیری ماشین
دادههای پرت چیست؟
دادههای پرت نقاط دادهای هستند که به طور قابل توجهی از سایر دادهها فاصله دارند. این نقاط میتوانند بسیار بالاتر یا بسیار پایینتر از سایر نقاط داده باشند و حضور آنها میتواند تأثیر قابل توجهی بر نتایج الگوریتمهای یادگیری ماشین بگذارد. این دادهها ممکن است به دلیل خطاهای اندازهگیری یا اجرایی ایجاد شوند. تحلیل دادههای پرت به عنوان تحلیل پرت یا دادهکاوی پرت شناخته میشود.
انواع دادههای پرت
دو نوع اصلی دادههای پرت وجود دارد:
- دادههای پرت جهانی (Global Outliers): این دادهها نقاطی هستند که به طور مجزا از بدنه اصلی دادهها فاصله زیادی دارند. شناسایی و حذف آنها اغلب آسان است.
- دادههای پرت زمینهای (Contextual Outliers): این دادهها نقاطی هستند که در یک زمینه خاص غیرعادی هستند، اما ممکن است در زمینههای دیگر پرت محسوب نشوند. شناسایی آنها اغلب دشوارتر است و ممکن است به اطلاعات اضافی یا دانش دامنه نیاز داشته باشد.
روشهای تشخیص دادههای پرت در یادگیری ماشین
تشخیص دادههای پرت نقش مهمی در اطمینان از کیفیت و دقت مدلهای یادگیری ماشین دارد. با شناسایی و حذف یا مدیریت مؤثر دادههای پرت، میتوان از سوگیری مدل، کاهش عملکرد و اختلال در تفسیرپذیری آن جلوگیری کرد. در ادامه به بررسی روشهای مختلف تشخیص دادههای پرت میپردازیم:
1. روشهای آماری
- Z-Score: این روش انحراف معیار نقاط داده را محاسبه میکند و دادههای پرت را به عنوان نقاطی با Z-Score بیشتر از یک آستانه مشخص (معمولاً ۳ یا ۳-) شناسایی میکند.
- دامنه بین چارکی (IQR): این روش دادههای پرت را به عنوان نقاطی شناسایی میکند که خارج از محدوده تعریفشده توسط Q1-k*(Q3-Q1) و Q3+k*(Q3-Q1) قرار دارند، جایی که Q1 و Q3 به ترتیب چارک اول و سوم هستند و k یک عامل (معمولاً ۱.۵) است.
2. روشهای مبتنی بر فاصله
- K-Nearest Neighbors (KNN): این روش دادههای پرت را به عنوان نقاطی شناسایی میکند که K همسایه نزدیک آنها از آنها فاصله زیادی دارند.
- عامل پرت محلی (LOF): این روش چگالی محلی نقاط داده را محاسبه میکند و دادههای پرت را به عنوان نقاطی با چگالی بسیار کمتر نسبت به همسایههایشان شناسایی میکند.
3. روشهای مبتنی بر خوشهبندی
- DBSCAN: این روش نقاط داده را بر اساس چگالی خوشهبندی میکند و دادههای پرت را به عنوان نقاطی که به هیچ خوشهای تعلق ندارند شناسایی میکند.
- خوشهبندی سلسلهمراتبی: این روش با ادغام یا تقسیم خوشهها بر اساس شباهت آنها، یک سلسلهمراتب از خوشهها ایجاد میکند. دادههای پرت میتوانند به عنوان خوشههایی که فقط یک نقطه داده دارند یا خوشههایی که به طور قابل توجهی کوچکتر از سایرین هستند شناسایی شوند.
4. سایر روشها
- جنگل جداسازی (Isolation Forest): این روش به طور تصادفی نقاط داده را با تقسیم ویژگیها جدا میکند و دادههای پرت را به عنوان نقاطی که به سرعت و به راحتی جدا شدهاند شناسایی میکند.
- ماشین بردار پشتیبان یککلاسه (OCSVM): این روش یک مرز حول دادههای عادی یاد میگیرد و دادههای پرت را به عنوان نقاطی که خارج از این مرز قرار دارند شناسایی میکند.
تکنیکهای مدیریت دادههای پرت در یادگیری ماشین
دادههای پرت، نقاط دادهای هستند که به طور قابل توجهی از اکثریت دادهها فاصله دارند و میتوانند تأثیرات منفی بر مدلهای یادگیری ماشین داشته باشند. برای مدیریت این دادهها، چندین تکنیک وجود دارد:
1. حذف
- این روش شامل شناسایی و حذف دادههای پرت از مجموعه داده قبل از آموزش مدل است. روشهای رایج عبارتند از:
- آستانهگذاری: دادههای پرت به عنوان نقاطی که از یک آستانه مشخص (مثلاً Z-Score > 3) فراتر میروند شناسایی میشوند.
- روشهای مبتنی بر فاصله: دادههای پرت بر اساس فاصله آنها از نزدیکترین همسایههایشان شناسایی میشوند.
- خوشهبندی: دادههای پرت به عنوان نقاطی که به هیچ خوشهای تعلق ندارند یا به خوشههای بسیار کوچک تعلق دارند شناسایی میشوند.
2. تبدیل
- این روش شامل تبدیل دادهها برای کاهش تأثیر دادههای پرت است. روشهای رایج عبارتند از:
- مقیاسگذاری: استانداردسازی یا نرمالسازی دادهها به گونهای که میانگین صفر و انحراف معیار یک داشته باشند.
- Winsorization: جایگزینی مقادیر پرت با نزدیکترین مقدار غیر پرت.
- تبدیل لگاریتمی: اعمال یک تبدیل لگاریتمی برای فشردهسازی دادهها و کاهش تأثیر مقادیر شدید.
3. برآورد مقاوم
- این روش شامل استفاده از الگوریتمهایی است که نسبت به دادههای پرت حساسیت کمتری دارند. برخی از نمونهها عبارتند از:
- رگرسیون مقاوم: الگوریتمهایی مانند رگرسیون L1 یا رگرسیون Huber نسبت به رگرسیون حداقل مربعات کمتر تحت تأثیر دادههای پرت قرار میگیرند.
- M-estimators: این الگوریتمها پارامترهای مدل را بر اساس یک تابع هدف مقاوم تخمین میزنند که تأثیر دادههای پرت را کاهش میدهد.
- الگوریتمهای خوشهبندی مقاوم به پرت: الگوریتمهایی مانند DBSCAN نسبت به حضور دادههای پرت حساسیت کمتری دارند.
4. مدلسازی دادههای پرت
- این روش شامل مدلسازی صریح دادههای پرت به عنوان یک گروه جداگانه است. این کار میتواند با روشهای زیر انجام شود:
- اضافه کردن یک ویژگی جداگانه: ایجاد یک ویژگی جدید که نشان میدهد یک نقطه داده پرت است یا خیر.
- استفاده از مدل مخلوط: آموزش یک مدل که فرض میکند دادهها از ترکیبی از چند توزیع آمدهاند، جایی که یک توزیع نشاندهنده دادههای پرت است.
اهمیت تشخیص دادههای پرت در یادگیری ماشین
تشخیص دادههای پرت در یادگیری ماشین به دلایل زیر مهم است:
- مدلهای سوگیرانه: دادههای پرت میتوانند مدل یادگیری ماشین را به سمت مقادیر پرت سوق دهند و منجر به عملکرد ضعیف در بقیه دادهها شوند.
- کاهش دقت: دادههای پرت میتوانند نویز را به دادهها وارد کنند و یادگیری الگوهای واقعی را برای مدل دشوار کنند.
- افزایش واریانس: دادههای پرت میتوانند واریانس مدل را افزایش دهند و آن را به تغییرات کوچک در دادهها حساس کنند.
- کاهش تفسیرپذیری: دادههای پرت میتوانند درک آنچه مدل از دادهها یاد گرفته است را دشوار کنند.
نتیجهگیری
تشخیص و مدیریت دادههای پرت جنبههای مهمی در ساخت مدلهای یادگیری ماشین قابل اعتماد و قوی هستند. با درک تأثیر دادههای پرت، انتخاب تکنیک مناسب برای دادهها و وظیفه خاص، و استفاده از دانش دامنه و تجسم دادهها، میتوان اطمینان حاصل کرد که مدلها بر روی دادههای دیدهنشده عملکرد خوبی داشته باشند و پیشبینیهای دقیق و قابل اعتمادی ارائه دهند.
سوالات متداول
- دادههای پرت در یادگیری ماشین چیست؟
- دادههای پرت نقاط دادهای هستند که به طور قابل توجهی از اکثریت دادهها فاصله دارند. این دادهها میتوانند به دلیل خطاها، ناهنجاریها یا رویدادهای نادر ایجاد شوند.
- چرا دادههای پرت برای مدلهای یادگیری ماشین مشکلساز هستند؟
- دادههای پرت میتوانند عملکرد مدلهای یادگیری ماشین را به چند روش تحت تأثیر قرار دهند:
- بیشبرازش: مدلها ممکن است به جای الگوهای اصلی دادهها، بر روی دادههای پرت تمرکز کنند.
- کاهش دقت: دادههای پرت میتوانند پیشبینیهای مدل را به سمت خود بکشند و منجر به پیشبینیهای نادرست برای سایر نقاط داده شوند.
- مدلهای ناپایدار: حضور دادههای پرت میتواند پیشبینیهای مدل را به تغییرات کوچک در دادهها حساس کند.
- دادههای پرت میتوانند عملکرد مدلهای یادگیری ماشین را به چند روش تحت تأثیر قرار دهند:
- چگونه میتوان دادههای پرت را تشخیص داد؟
- چندین روش برای تشخیص دادههای پرت وجود دارد، از جمله:
- اندازهگیریهای مبتنی بر فاصله: این اندازهگیریها، مانند Z-Score و دامنه بین چارکی (IQR)، فاصله یک نقطه داده از مرکز توزیع دادهها را محاسبه میکنند.
- تکنیکهای تجسمی: تکنیکهایی مانند نمودار جعبهای و نمودار پراکندگی میتوانند به صورت بصری نقاط دادهای که از اکثریت دادهها فاصله زیادی دارند را شناسایی کنند.
- الگوریتمهای خوشهبندی: الگوریتمهای خوشهبندی میتوانند به طور خودکار نقاط داده مشابه را گروهبندی کنند و دادههای پرت را به عنوان خوشههای جداگانه شناسایی کنند.
- چندین روش برای تشخیص دادههای پرت وجود دارد، از جمله:
- چگونه میتوان دادههای پرت را مدیریت کرد؟
- چندین رویکرد برای مدیریت دادههای پرت در یادگیری ماشین وجود دارد:
- حذف دادههای پرت: این یک رویکرد ساده است اما میتواند منجر به از دست رفتن اطلاعات شود.
- برش: دادههای پرت به جای حذف کامل، به یک مقدار مشخص محدود میشوند.
- تبدیل: دادهها میتوانند تبدیل شوند تا تأثیر دادههای پرت کاهش یابد، مانند استفاده از تبدیلهای لگاریتمی برای دادههای چولگی.
- مدلهای مقاوم: برخی مدلها نسبت به دادههای پرت حساسیت کمتری دارند، مانند درختهای تصمیم و ماشینهای بردار پشتیبان.
- چندین رویکرد برای مدیریت دادههای پرت در یادگیری ماشین وجود دارد:
- چه زمانی باید دادههای پرت را حذف کرد؟
- حذف دادههای پرت زمانی مفید است که احتمالاً به دلیل خطاها یا ناهنجاریها ایجاد شدهاند. با این حال، باید از حذف دادههای پرتی که نمایانگر رویدادهای واقعی اما نادر در دادهها هستند، اجتناب کرد


دیدگاهتان را بنویسید