
الگوریتم جنگل تصادفی در یادگیری ماشین

جنگل تصادفی مجموعهای از درختهای تصمیم است که برای انجام پیشبینیها با هم همکاری میکنند. در این مقاله، نحوه عملکرد الگوریتم جنگل تصادفی و نحوه استفاده از آن توضیح داده شده است.
درک شهودی الگوریتم جنگل تصادفی
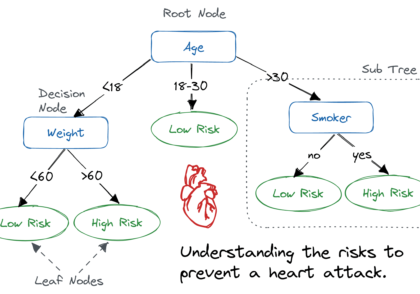
الگوریتم جنگل تصادفی یک تکنیک قدرتمند در یادگیری ماشین است که برای انجام پیشبینیها به کار میرود. در این الگوریتم، ابتدا پیشبینیهای درختهای تصمیم مختلف گرفته میشود و سپس نتایج آنها با هم ترکیب میشوند. این الگوریتم به طور گستردهای برای وظایف طبقهبندی و رگرسیون استفاده میشود.
- جنگل تصادفی نوعی طبقهبند است که از چندین درخت تصمیم برای انجام پیشبینیها استفاده میکند.
- این الگوریتم از بخشهای تصادفی دادهها برای آموزش هر درخت استفاده میکند و سپس نتایج را با میانگینگیری ترکیب میکند. این رویکرد به بهبود دقت پیشبینیها کمک میکند.
- جنگل تصادفی بر اساس یادگیری ترکیبی (Ensemble Learning) ساخته شده است.
تصور کنید از یک گروه از دوستان برای مشورت در مورد مقصد تعطیلات خود نظر میخواهید. هر دوست پیشنهاد خود را بر اساس دیدگاهها و ترجیحات منحصر به فرد خود میدهد (درختهای تصمیم که بر روی زیرمجموعههای مختلف دادهها آموزش دیدهاند). سپس شما تصمیم نهایی خود را با توجه به نظر اکثریت یا میانگین پیشنهادات آنها میگیرید (پیشبینی ترکیبی).
ویژگیهای کلیدی جنگل تصادفی
- مدیریت دادههای گمشده: به طور خودکار مقادیر گمشده را در هنگام آموزش مدیریت میکند و نیاز به تکمیل دستی دادهها را از بین میبرد.
- رتبهبندی ویژگیها: الگوریتم ویژگیها را بر اساس اهمیت آنها در انجام پیشبینیها رتبهبندی میکند و اطلاعات مفیدی برای انتخاب ویژگیها و تفسیر مدل ارائه میدهد.
- مقیاسپذیری بالا: الگوریتم به خوبی با دادههای بزرگ و پیچیده سازگار است و کاهش عملکرد قابل توجهی ندارد.
- انعطافپذیری بالا: این الگوریتم میتواند برای وظایف طبقهبندی (برای پیشبینی دستهها) و رگرسیون (برای پیشبینی مقادیر پیوسته) اعمال شود.
نحوه عملکرد الگوریتم جنگل تصادفی
الگوریتم جنگل تصادفی در چندین مرحله کار میکند:
- ایجاد درختهای تصمیم: جنگل تصادفی چندین درخت تصمیم را با استفاده از نمونههای تصادفی دادهها میسازد. هر درخت بر روی زیرمجموعهای متفاوت از دادهها آموزش میبیند که این باعث منحصر به فرد شدن هر درخت میشود.
- انتخاب تصادفی ویژگیها: هنگام ایجاد هر درخت، الگوریتم به طور تصادفی یک زیرمجموعه از ویژگیها را برای تقسیمبندی دادهها انتخاب میکند، به جای اینکه از تمام ویژگیها به صورت همزمان استفاده کند. این به درختها تنوع میبخشد.
- پیشبینیها: هر درخت تصمیم در جنگل پیشبینیهایی بر اساس دادههایی که روی آنها آموزش دیده، انجام میدهد.
- ترکیب پیشبینیها: پیشبینی نهایی با ترکیب نتایج همه درختها انجام میشود.
- برای وظایف طبقهبندی، پیشبینی نهایی با رایگیری اکثریت انجام میشود. یعنی دستهای که بیشتر درختها پیشبینی کردهاند، پیشبینی نهایی است.
- برای وظایف رگرسیون، پیشبینی نهایی با میانگین پیشبینیهای همه درختها انجام میشود.
- اجتناب از بیشبرازش: تصادفی بودن انتخاب نمونههای داده و ویژگیها کمک میکند تا مدل از بیشبرازش جلوگیری کند و پیشبینیها دقیقتر و قابل اعتمادتر شوند.
فرضیات جنگل تصادفی
- هر درخت تصمیم مستقل است: هر درخت در جنگل پیشبینیهای خود را انجام میدهد بدون اینکه به درختهای دیگر وابسته باشد.
- از بخشهای تصادفی دادهها استفاده میشود: هر درخت با استفاده از نمونههای تصادفی و ویژگیها ساخته میشود تا خطاها کاهش یابد.
- دادههای کافی مورد نیاز است: دادههای کافی برای این که درختها متفاوت باشند و الگوهای منحصر به فردی یاد بگیرند ضروری است.
- پیشبینیهای متفاوت دقت را بهبود میبخشند: ترکیب پیشبینیهای درختهای مختلف به نتایج نهایی دقت بیشتری میدهد.
پیادهسازی جنگل تصادفی برای وظایف طبقهبندی
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
import warnings
warnings.filterwarnings('ignore')
# URL صحیح برای مجموعه داده
url = "https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv"
titanic_data = pd.read_csv(url)
# حذف ردیفهایی که مقدار 'Survived' آنها گم شده است
titanic_data = titanic_data.dropna(subset=['Survived'])
# ویژگیها و متغیر هدف
X = titanic_data[['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare']]
y = titanic_data['Survived']
# رمزگذاری ستون 'Sex'
X.loc[:, 'Sex'] = X['Sex'].map({'female': 0, 'male': 1})
# پر کردن مقادیر گم شده 'Age' با میانه
X.loc[:, 'Age'].fillna(X['Age'].median(), inplace=True)
# تقسیم دادهها به مجموعههای آموزشی و آزمایشی
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ایجاد مدل RandomForestClassifier
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# آموزش مدل بر روی دادههای آموزشی
rf_classifier.fit(X_train, y_train)
# انجام پیشبینیها
y_pred = rf_classifier.predict(X_test)
# محاسبه دقت و گزارش طبقهبندی
accuracy = accuracy_score(y_test, y_pred)
classification_rep = classification_report(y_test, y_pred)
# چاپ نتایج
print(f"Accuracy: {accuracy:.2f}")
print("\nClassification Report:\n", classification_rep)
# پیشبینی نمونه
sample = X_test.iloc[0:1] # نگه داشتن به صورت DataFrame برای همخوانی با ورودی مدل
prediction = rf_classifier.predict(sample)
# نمایش نمونه و پیشبینی
sample_dict = sample.iloc[0].to_dict()
print(f"\nSample Passenger: {sample_dict}")
print(f"Predicted Survival: {'Survived' if prediction[0] == 1 else 'Did Not Survive'}")
خروجی:
Accuracy: 0.80
Classification Report:
precision recall f1-score support
0 0.82 0.85 0.83 105
1 0.77 0.73 0.75 74
accuracy 0.80 179
macro avg 0.79 0.79 0.79 179
weighted avg 0.80 0.80 0.80 179
Sample Passenger: {'Pclass': 3, 'Sex': 1, 'Age': 28.0, 'SibSp': 1, 'Parch': 1, 'Fare': 15.2458}
Predicted Survival: Did Not Survive
در کد بالا، از Random Forest Classifier برای تحلیل مجموعه داده تایتانیک استفاده شده است. این مدل از دادههای آموزشی یاد میگیرد و بر روی مجموعه داده آزمایشی تست میشود. عملکرد مدل با استفاده از گزارش طبقهبندی ارزیابی میشود و پیشبینی یک نمونه تصادفی نمایش داده میشود.
پیادهسازی جنگل تصادفی برای وظایف رگرسیون
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, r2_score
# بارگذاری مجموعه داده مسکن کالیفرنیا
california_housing = fetch_california_housing()
california_data = pd.DataFrame(california_housing.data, columns=california_housing.feature_names)
california_data['MEDV'] = california_housing.target
# ویژگیها و متغیر هدف
X = california_data.drop('MEDV', axis=1)
y = california_data['MEDV']
# تقسیم دادهها به مجموعههای آموزشی و آزمایشی
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# ایجاد مدل RandomForestRegressor
rf_regressor = RandomForestRegressor(n_estimators=100, random_state=42)
# آموزش مدل
rf_regressor.fit(X_train, y_train)
# انجام پیشبینیها
y_pred = rf_regressor.predict(X_test)
# محاسبه معیارها
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# پیشبینی نمونه
single_data = X_test.iloc[0].values.reshape(1, -1)
predicted_value = rf_regressor.predict(single_data)
print(f"Predicted Value: {predicted_value[0]:.2f}")
print(f"Actual Value: {y_test.iloc[0]:.2f}")
# چاپ نتایج
print(f"Mean Squared Error: {mse:.2f}")
print(f"R-squared Score: {r2:.2f}")
خروجی:
Predicted Value: 0.51
Actual Value: 0.48
Mean Squared Error: 0.26
R-squared Score: 0.80
در کد بالا، از Random Forest Regressor برای تحلیل مجموعه داده مسکن کالیفرنیا استفاده شده است. این مدل پس از آموزش، پیشبینیهایی برای دادههای آزمایشی انجام میدهد و دقت مدل با استفاده از Mean Squared Error و R-squared ارزیابی میشود.
مزایای جنگل تصادفی
- جنگل تصادفی پیشبینیهای بسیار دقیقی حتی با دادههای بزرگ فراهم میکند.
- میتواند به خوبی با دادههای گمشده برخورد کند بدون اینکه دقت آن کاهش یابد.
- نیاز به نرمالسازی یا استانداردسازی دادهها ندارد.
- ترکیب درختهای تصمیم مختلف ریسک بیشبرازش مدل را کاهش میدهد.
محدودیتهای جنگل تصادفی
- میتواند به ویژه با تعداد زیادی درخت، محاسباتی پرهزینه باشد.
- تفسیر مدل نسبت به مدلهای سادهتری مانند درخت تصمیم دشوارتر است.
سوالات متداول درباره جنگل تصادفی
جنگل تصادفی برای چه مواردی استفاده میشود؟
- جنگل تصادفی یک الگوریتم یادگیری ماشین است که برای وظایف طبقهبندی و رگرسیون استفاده میشود. این الگوریتم پیشبینیها را با ترکیب نتایج چندین درخت تصمیم انجام میدهد. از آن در برنامههایی مانند پیشبینی قیمت خانهها، طبقهبندی تصاویر و تحلیل رفتار مشتری استفاده میشود.
تفاوت بین درخت تصمیم و جنگل تصادفی چیست؟
- درخت تصمیم یک مدل مستقل است که پیشبینیها را بر اساس یک سری تصمیمات انجام میدهد، در حالی که جنگل تصادفی یک گروه از درختهای تصمیم است که با هم کار میکنند تا دقت پیشبینیها را بهبود بخشند. دقت درخت تصمیم کم است و حساس به تغییرات دادههای آموزشی است، در حالی که جنگل تصادفی دقت بهتری دارد.
تفاوت بین XGBoost و جنگل تصادفی چیست؟
- جنگل تصادفی یک الگوریتم یادگیری گروهی است که بر اساس bagging عمل میکند، جایی که چندین درخت تصمیم به طور مستقل آموزش میبینند و پیشبینیهای آنها میانگینگیری یا رایگیری میشود. در مقابل، XGBoost یک الگوریتم boosting است که به تدریج درختهای ضعیفتر را آموزش میدهد و هر درخت جدید روی اشتباهات درخت قبلی تمرکز میکند تا عملکرد کلی را بهبود بخشد.


1 دیدگاه
به گفتگوی ما بپیوندید و دیدگاه خود را با ما در میان بگذارید.
پایتون واقعا کار باهاش راحته