
یادگیری ماشین تحت نظارت Supervised learning
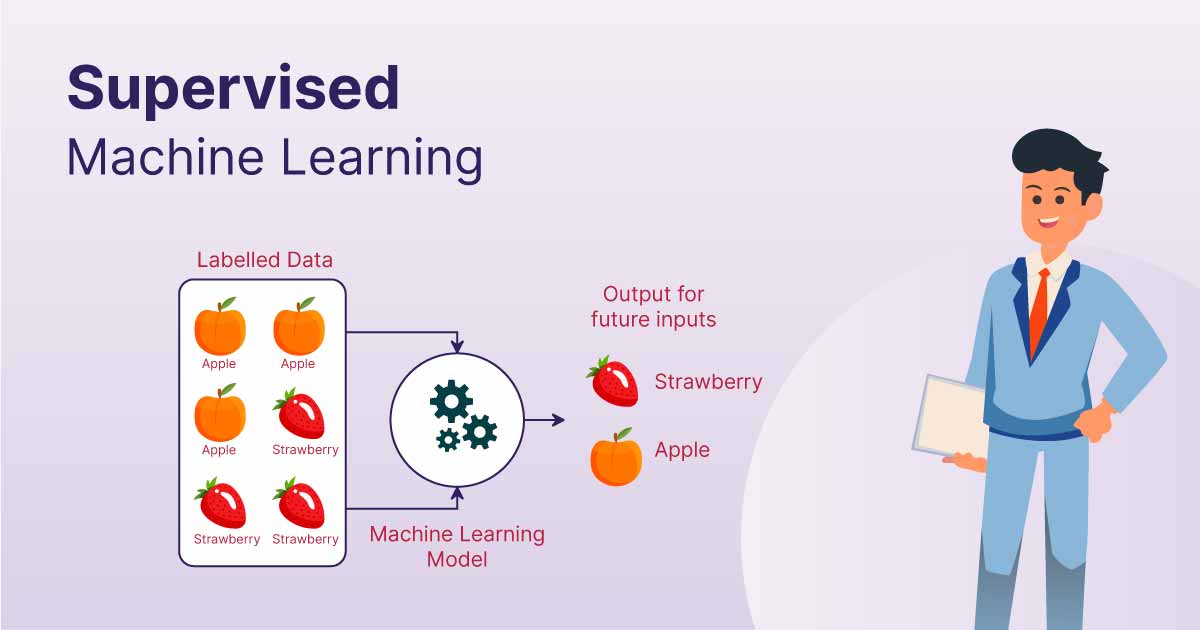
یادگیری ماشین تحت نظارت یک رویکرد اساسی در یادگیری ماشین و هوش مصنوعی است. این روش شامل آموزش یک مدل با استفاده از دادههای برچسبگذاریشده است، جایی که هر ورودی دارای خروجی صحیح متناظر با آن است. این فرآیند شبیه به یک معلم است که یک دانشآموز را راهنمایی میکند، از این رو اصطلاح “یادگیری تحت نظارت” به کار میرود. در این مقاله، اجزای کلیدی یادگیری تحت نظارت، انواع الگوریتمهای مورد استفاده و برخی مثالهای عملی از نحوه عملکرد آن را بررسی خواهیم کرد.
یادگیری ماشین تحت نظارت چیست؟
همانطور که قبلاً توضیح دادیم، یادگیری تحت نظارت نوعی از یادگیری ماشین است که در آن یک مدل با استفاده از دادههای برچسبگذاریشده آموزش داده میشود، به این معنی که هر ورودی با خروجی صحیح متناظر است. مدل با مقایسه پیشبینیهای خود با پاسخهای واقعی ارائهشده در دادههای آموزشی یاد میگیرد. با گذشت زمان، خود را تنظیم میکند تا خطاها را به حداقل برساند و دقت را بهبود بخشد. هدف یادگیری تحت نظارت این است که هنگام دریافت دادههای جدید و نادیده، پیشبینیهای دقیقی انجام دهد.
به عنوان مثال، اگر مدلی برای تشخیص ارقام دستنویس آموزش داده شود، از آنچه آموخته است استفاده میکند تا اعداد جدیدی را که قبلاً ندیده است، به درستی شناسایی کند.
یادگیری تحت نظارت را میتوان در قالبهای مختلفی از جمله طبقهبندی تحت نظارت و رگرسیون تحت نظارت اعمال کرد، که این امر آن را به یک تکنیک حیاتی در هوش مصنوعی و دادهکاوی تحت نظارت تبدیل میکند.
یک مفهوم اساسی در یادگیری تحت نظارت، یادگیری یک کلاس از روی نمونهها است. این شامل ارائه نمونههایی به مدل است که در آن برچسب صحیح شناخته شده است، مانند یادگیری برای طبقهبندی تصاویر گربهها و سگها از طریق مشاهده نمونههای برچسبگذاریشده از هر دو. مدل سپس ویژگیهای متمایز هر کلاس را یاد میگیرد و از این دانش برای طبقهبندی تصاویر جدید استفاده میکند.
یادگیری ماشین تحت نظارت چگونه کار میکند؟
یک الگوریتم یادگیری تحت نظارت شامل ویژگیهای ورودی و برچسبهای خروجی متناظر است. این فرآیند از طریق مراحل زیر کار میکند:
- دادههای آموزشی: مدل با یک مجموعه داده آموزشی ارائه میشود که شامل دادههای ورودی (ویژگیها) و دادههای خروجی متناظر (برچسبها یا متغیرهای هدف) است.
- فرآیند یادگیری: الگوریتم دادههای آموزشی را پردازش کرده و روابط بین ویژگیهای ورودی و برچسبهای خروجی را یاد میگیرد. این کار با تنظیم پارامترهای مدل برای به حداقل رساندن تفاوت بین پیشبینیهای آن و برچسبهای واقعی انجام میشود.
پس از آموزش، مدل با استفاده از یک مجموعه داده آزمایشی ارزیابی میشود تا دقت و عملکرد آن اندازهگیری شود. سپس عملکرد مدل با تنظیم پارامترها و استفاده از تکنیکهایی مانند اعتبارسنجی متقابل برای متعادلسازی تورش و واریانس بهینهسازی میشود. این کار تضمین میکند که مدل بتواند به خوبی روی دادههای جدید و دیدهنشده تعمیم دهد.
به طور خلاصه، یادگیری ماشین تحت نظارت شامل آموزش یک مدل با دادههای برچسبگذاریشده برای یادگیری الگوها و روابط است، که سپس از آن برای انجام پیشبینیهای دقیق بر روی دادههای جدید استفاده میکند.
بیایید ببینیم که چگونه یک مدل یادگیری تحت نظارت روی یک مجموعه داده آموزش میبیند تا یک تابع نگاشت بین ورودی و خروجی را بیاموزد و سپس از این تابع آموختهشده برای انجام پیشبینیها روی دادههای جدید استفاده میشود:
در تصویر بالا:
- مرحله آموزش شامل تغذیه الگوریتم با دادههای برچسبگذاریشده است، جایی که هر نقطه داده با خروجی صحیح آن جفت شده است. الگوریتم الگوها و روابط بین دادههای ورودی و خروجی را یاد میگیرد.
- مرحله آزمایش شامل تغذیه الگوریتم با دادههای جدید و دیدهنشده و ارزیابی توانایی آن در پیشبینی خروجی صحیح بر اساس الگوهای آموختهشده است.
انواع یادگیری تحت نظارت در یادگیری ماشین
حالا، یادگیری تحت نظارت را میتوان برای دو نوع اصلی از مسائل به کار برد:
- طبقهبندی: جایی که خروجی یک متغیر دستهای است (مثلاً ایمیلهای اسپم در مقابل غیر اسپم، بله در مقابل خیر).
- رگرسیون: جایی که خروجی یک متغیر پیوسته است (مثلاً پیشبینی قیمت خانه، قیمت سهام).
در حین آموزش مدل، دادهها معمولاً به نسبت ۸۰:۲۰ تقسیم میشوند، یعنی ۸۰٪ به عنوان داده آموزشی و ۲۰٪ باقیمانده به عنوان داده آزمایشی. در دادههای آموزشی، هم ورودی و هم خروجی را برای ۸۰٪ از دادهها تغذیه میکنیم. مدل فقط از دادههای آموزشی یاد میگیرد. برای ساخت مدل، از الگوریتمهای مختلف یادگیری تحت نظارت استفاده میکنیم (که در بخش بعدی به تفصیل بررسی خواهیم کرد).
بیایید ابتدا دادههای مربوط به طبقهبندی و رگرسیون را از طریق جدول زیر درک کنیم:
هر دو شکل بالا دارای مجموعه دادههای برچسبگذاریشدهای به شرح زیر هستند:
- شکل A: مجموعه دادهای از یک فروشگاه خرید است که برای پیشبینی اینکه آیا مشتری یک محصول خاص را خریداری خواهد کرد یا خیر، بر اساس جنسیت، سن و حقوق او مفید است.
- ورودی: جنسیت، سن، حقوق
- خروجی: خرید کرده است یا خیر (۰ یا ۱)؛ ۱ به معنی این است که مشتری خرید خواهد کرد و ۰ به معنی این است که مشتری آن را خریداری نخواهد کرد.
- شکل B: یک مجموعه داده هواشناسی است که برای پیشبینی سرعت باد بر اساس پارامترهای مختلف استفاده میشود.
- ورودی: نقطه شبنم، دما، فشار، رطوبت نسبی، جهت باد
- خروجی: سرعت باد
مثالهای عملی یادگیری نظارتشده
چند مثال عملی از یادگیری نظارتشده در صنایع مختلف:
- تشخیص تقلب در بانکداری: از الگوریتمهای یادگیری نظارتشده روی دادههای تراکنش تاریخی استفاده میشود و مدلها با دادههای برچسبخورده از تراکنشهای واقعی و تقلبی آموزش داده میشوند تا الگوهای تقلب را بهطور دقیق پیشبینی کنند.
- پیشبینی بیماری پارکینسون: بیماری پارکینسون یک اختلال پیشرونده است که بر سیستم عصبی و بخشهایی از بدن که تحت کنترل اعصاب قرار دارند تأثیر میگذارد.
- پیشبینی ترک مشتریان: از تکنیکهای یادگیری نظارتشده برای تجزیه و تحلیل دادههای تاریخی مشتریان استفاده میشود تا ویژگیهای مربوط به نرخ ترک مشتری را شناسایی کرده و پیشبینی کنند که مشتری باقی میماند یا خیر.
- طبقهبندی سلولهای سرطانی: از یادگیری نظارتشده برای شناسایی سلولهای سرطانی بر اساس ویژگیهای آنها و تعیین اینکه آیا “بدخیم” یا “خوشخیم” هستند استفاده میشود.
- پیشبینی قیمت سهام: از یادگیری نظارتشده برای پیشبینی سیگنالی استفاده میشود که نشان میدهد آیا خرید یک سهام خاص مفید خواهد بود یا خیر.
الگوریتمهای یادگیری نظارتشده
یادگیری نظارتشده میتواند به چندین نوع مختلف تقسیم شود که هرکدام ویژگیها و کاربردهای خاص خود را دارند. در اینجا برخی از رایجترین انواع الگوریتمهای یادگیری نظارتشده آورده شده است:
- رگرسیون خطی: رگرسیون خطی یک نوع الگوریتم یادگیری نظارتشده است که برای پیشبینی یک مقدار خروجی پیوسته استفاده میشود. این یکی از سادهترین و پرکاربردترین الگوریتمها در یادگیری نظارتشده است.
- رگرسیون لجستیک: رگرسیون لجستیک یک نوع الگوریتم طبقهبندی یادگیری نظارتشده است که برای پیشبینی یک متغیر خروجی دودویی استفاده میشود.
- درختهای تصمیمگیری: درخت تصمیمگیری یک ساختار درختی است که برای مدلسازی تصمیمات و پیامدهای احتمالی آنها استفاده میشود. هر گره داخلی درخت نشاندهنده یک تصمیم است، در حالی که هر گره برگ نمایانگر یک نتیجه ممکن است.
- جنگلهای تصادفی: جنگلهای تصادفی از چندین درخت تصمیمگیری تشکیل شدهاند که با هم برای انجام پیشبینیها کار میکنند. هر درخت درخت جنگل روی زیرمجموعهای مختلف از ویژگیها و دادههای ورودی آموزش داده میشود. پیشبینی نهایی با تجمیع پیشبینیهای تمام درختها در جنگل انجام میشود.
- ماشین بردار پشتیبان (SVM): الگوریتم SVM یک صفحهی هایپرپلان ایجاد میکند تا فضای n-بعدی را به کلاسها تقسیم کرده و دستهبندی درست نقاط داده جدید را شناسایی کند. موارد افراطی که کمک به ایجاد هایپرپلان میکنند به نام بردارهای پشتیبان شناخته میشوند.
- K-نزدیکترین همسایگان (KNN): KNN با یافتن k نمونه آموزش که نزدیکترین به ورودی داده شده هستند، پیشبینی میکند که کلاس یا مقدار براساس اکثریت کلاس یا میانگین این همسایگان باشد. عملکرد KNN میتواند تحت تأثیر انتخاب k و معیار فاصله برای اندازهگیری نزدیکی قرار گیرد.
- تقویت گرادیان: تقویت گرادیان با ترکیب یادگیرندگان ضعیف، مانند درختهای تصمیمگیری، یک مدل قوی ایجاد میکند. این فرآیند به طور مکرر مدلهای جدیدی میسازد که خطاهای مدلهای قبلی را اصلاح میکنند.
- الگوریتم بیز ساده: الگوریتم بیز ساده یک الگوریتم یادگیری نظارتشده است که بر اساس اعمال قضیه بیز با فرض “ساده” استقلال ویژگیها از یکدیگر با توجه به برچسب کلاس است.
خلاصه الگوریتمهای یادگیری نظارتشده در جدول:
| الگوریتم | رگرسیون، طبقهبندی | هدف | روش | موارد استفاده |
|---|---|---|---|---|
| رگرسیون خطی | رگرسیون | پیشبینی مقادیر خروجی پیوسته | معادله خطی که مجموع مربعات باقیمانده را کمینه میکند | پیشبینی مقادیر پیوسته |
| رگرسیون لجستیک | طبقهبندی | پیشبینی متغیر خروجی دودویی | تابع لجستیک که رابطه خطی را تبدیل میکند | وظایف طبقهبندی دودویی |
| درختهای تصمیمگیری | هر دو | مدلسازی تصمیمات و پیامدها | ساختار درختی با تصمیمات و پیامدها | وظایف طبقهبندی و رگرسیون |
| جنگلهای تصادفی | هر دو | دقت طبقهبندی و رگرسیون را بهبود میبخشد | ترکیب چندین درخت تصمیمگیری | کاهش بیشبرازش، بهبود دقت پیشبینی |
| SVM | هر دو | ایجاد هایپرپلان برای طبقهبندی یا پیشبینی مقادیر پیوسته | حداکثر کردن فاصله بین کلاسها یا پیشبینی مقادیر پیوسته | وظایف طبقهبندی و رگرسیون |
| KNN | هر دو | پیشبینی کلاس یا مقدار براساس k همسایگان نزدیک | یافتن k همسایه نزدیک و پیشبینی بر اساس اکثریت یا میانگین | وظایف طبقهبندی و رگرسیون، حساس به دادههای پر سر و صدا |
| تقویت گرادیان | هر دو | ترکیب یادگیرندگان ضعیف برای ایجاد مدل قوی | اصلاح خطاهای مدلهای قبلی با مدلهای جدید | وظایف طبقهبندی و رگرسیون برای بهبود دقت پیشبینی |
| بیز ساده | طبقهبندی | پیشبینی کلاس بر اساس فرض استقلال ویژگیها | قضیه بیز با فرض استقلال ویژگیها | طبقهبندی متن، فیلتر اسپم، تحلیل احساسات، پزشکی |
آموزش یک مدل یادگیری نظارتشده: مراحل کلیدی
هدف از یادگیری نظارتشده این است که مدل بهخوبی به دادههای جدید تعمیم یابد. آموزش یک مدل برای یادگیری نظارتشده شامل چندین مرحله حیاتی است که هرکدام به آمادهسازی مدل برای انجام پیشبینیها یا تصمیمات دقیق بر اساس دادههای برچسبخورده کمک میکند. در اینجا مراحل کلیدی آموزش یک مدل یادگیری نظارتشده آورده شده است:
- جمعآوری و پیشپردازش دادهها: یک مجموعه داده برچسبخورده شامل ویژگیهای ورودی و برچسبهای خروجی هدف جمعآوری کنید. دادهها را تمیز کرده، مقادیر گمشده را پردازش کرده و ویژگیها را مقیاسبندی کنید تا کیفیت بالا برای الگوریتمهای یادگیری نظارتشده فراهم شود.
- تقسیم دادهها: دادهها را به مجموعه آموزشی (80%) و مجموعه آزمایشی (20%) تقسیم کنید.
- انتخاب مدل: الگوریتمهای مناسب را بر اساس نوع مشکل انتخاب کنید. این مرحله برای یادگیری مؤثر نظارتشده در هوش مصنوعی بسیار مهم است.
- آموزش مدل: دادههای ورودی و برچسبهای خروجی را به مدل بدهید و اجازه دهید الگوها را با تنظیم پارامترهای داخلی بیاموزد.
- ارزیابی مدل: مدل آموزشدیده را بر روی مجموعه آزمایشی نادیده قرار داده و عملکرد آن را با استفاده از معیارهای مختلف ارزیابی کنید.
- تنظیم هایپرپارامترها: تنظیمات مربوط به فرآیند آموزش (مانند نرخ یادگیری) را با استفاده از تکنیکهایی مانند جستجوی شبکهای و اعتبارسنجی متقابل تنظیم کنید.
- انتخاب نهایی مدل و آزمایش: مدل را بر روی مجموعه داده کامل با بهترین هایپرپارامترها مجدداً آموزش دهید و عملکرد آن را بر روی مجموعه آزمایشی بررسی کنید تا آمادهسازی برای استقرار را تضمین کنید.
- استقرار مدل: مدل تأیید شده را برای پیشبینی بر روی دادههای جدید، نادیدهگرفته شده، مستقر کنید.
با دنبال کردن این مراحل، مدلهای یادگیری نظارتشده میتوانند بهطور مؤثر برای انجام وظایف مختلف از یادگیری یک کلاس از مثالها تا پیشبینی در کاربردهای دنیای واقعی آموزش ببینند.
مزایا و معایب یادگیری نظارتشده
مزایای یادگیری نظارتشده
قدرت یادگیری نظارتشده در توانایی آن برای پیشبینی دقیق الگوها و اتخاذ تصمیمات مبتنی بر دادهها در بسیاری از کاربردها نهفته است. در اینجا برخی از مزایای یادگیری نظارتشده آورده شده است:
- یادگیری نظارتشده در پیشبینی دقیق الگوها و اتخاذ تصمیمات مبتنی بر دادهها برجسته است.
- دادههای آموزشی برچسبخورده برای یادگیری روابط ورودی-خروجی بهطور مؤثر بسیار مهم است.
- یادگیری ماشین نظارتشده شامل وظایفی مانند طبقهبندی و رگرسیون نظارتشده است.
- کاربردها شامل مسائل پیچیدهای مانند شناسایی تصویر و پردازش زبان طبیعی است.
- معیارهای ارزیابی معتبر (دقت، دقت، فراخوانی، نمره F1) برای ارزیابی عملکرد مدلهای یادگیری نظارتشده ضروری هستند.
- مزایای یادگیری نظارتشده شامل ایجاد مدلهای پیچیده برای پیشبینیهای دقیق بر روی دادههای جدید است.
- یادگیری نظارتشده به دادههای آموزشی برچسبخورده زیادی نیاز دارد و اثربخشی آن بستگی به کیفیت و نمایندگی دادهها دارد.
معایب یادگیری نظارتشده
با وجود مزایای روشهای یادگیری نظارتشده، معایب قابل توجهی نیز وجود دارد:
- بیشبرازش: مدلها ممکن است بر روی دادههای آموزشی بیشبرازش شوند که منجر به عملکرد ضعیف بر روی دادههای جدید میشود زیرا نویز در یادگیری ماشین نظارتشده ضبط میشود.
- مهندسی ویژگی: استخراج ویژگیهای مرتبط بسیار مهم است اما میتواند زمانبر باشد و نیاز به تخصص دامنه در کاربردهای یادگیری نظارتشده دارد.
- سوگیری در مدلها: سوگیری در دادههای آموزشی ممکن است منجر به پیشبینیهای ناعادلانه در الگوریتمهای یادگیری نظارتشده شود.
- وابستگی به دادههای برچسبخورده: یادگیری نظارتشده بهطور عمده به دادههای آموزشی برچسبخورده وابسته است که میتواند پرهزینه و زمانبر برای بهدست آوردن باشد، که این موضوع چالشی برای تکنیکهای یادگیری نظارتشده بهوجود میآورد.
نتیجهگیری
یادگیری نظارتشده یک شاخه قدرتمند از یادگیری ماشین است که بر یادگیری یک کلاس از مثالهایی که در طول آموزش فراهم شده است، متمرکز است. با استفاده از الگوریتمهای یادگیری نظارتشده، مدلها میتوانند برای پیشبینی بر اساس دادههای برچسبخورده آموزش ببینند. اثربخشی یادگیری ماشین نظارتشده در توانایی آن برای تعمیم از دادههای آموزشی به دادههای جدید و نادیدهگرفته شده است که این موضوع آن را برای بسیاری از کاربردها، از شناسایی تصویر تا پیشبینی مالی، بسیار ارزشمند میسازد.
درک انواع الگوریتمهای یادگیری نظارتشده و ابعاد یادگیری ماشین نظارتشده برای انتخاب الگوریتم مناسب برای حل مسائل خاص ضروری است. همانطور که ما به بررسی انواع مختلف یادگیری نظارتشده و پالایش این تکنیکها ادامه میدهیم، تأثیر یادگیری نظارتشده در یادگیری ماشین تنها افزایش خواهد یافت و نقشی حیاتی در پیشبرد راهحلهای مبتنی بر هوش مصنوعی ایفا خواهد کرد.
یادگیری ماشین نظارتشده – سوالات متداول
الگوریتمهای یادگیری نظارتشده در یادگیری ماشین چگونه کار میکنند؟
در الگوریتمهای یادگیری نظارتشده، مدل با وارد کردن دادههای برچسبخورده آموزش داده میشود. الگوریتم با توجه به تفاوت میان پیشبینیهای مدل و برچسبهای واقعی، پارامترهای خود را تنظیم کرده و عملکرد خود را بهطور مداوم بهبود میبخشد.
تعریف یادگیری نظارتشده چیست؟
تعریف یادگیری نظارتشده به فرآیند استفاده از جفتهای ورودی-خروجی برای آموزش یک مدل اشاره دارد، جایی که مدل میآموزد که ورودیها (ویژگیها) را به خروجیها (برچسبها) نگاشت کند.
آیا میتوانید مثالهایی از یادگیری نظارتشده ارائه دهید؟
مثالهایی از یادگیری نظارتشده شامل تشخیص هرزنامه در ایمیلها، شناسایی تصویر و نگهداری پیشبینی شده است که در آن دادههای تاریخی برای پیشبینی رویدادهای آینده استفاده میشود.
انواع یادگیری نظارتشده چیست؟
اصلیترین انواع یادگیری نظارتشده شامل طبقهبندی (دستهبندی دادهها به کلاسها) و رگرسیون (پیشبینی نتایج پیوسته) هستند.
یادگیری نظارتشده چگونه در هوش مصنوعی اعمال میشود؟
یادگیری نظارتشده بهطور گسترده در هوش مصنوعی برای وظایفی مانند طبقهبندی تصویر، پردازش زبان طبیعی و سیستمهای توصیه استفاده میشود.
برخی از الگوریتمهای محبوب یادگیری ماشین نظارتشده کدامند؟
برخی از الگوریتمهای رایج یادگیری ماشین نظارتشده شامل درختهای تصمیمگیری، ماشینهای بردار پشتیبان (SVM)، K-نزدیکترین همسایگان (KNN) و رگرسیون خطی هستند.
اهمیت یادگیری نظارتشده در یادگیری ماشین چیست؟
یادگیری نظارتشده در یادگیری ماشین بسیار مهم است زیرا این امکان را فراهم میکند که مدلهایی ساخته شوند که قادر به پیشبینیهای دقیق بر اساس دادههای تاریخی باشند که برای کاربردهایی مانند تشخیص هرزنامه، امتیازدهی اعتباری و تشخیص پزشکی ضروری است.
تکنیکهای یادگیری نظارتشده چگونه با دادههای نامتوازن برخورد میکنند؟
تکنیکهای یادگیری نظارتشده میتوانند با استفاده از روشهایی مانند نمونهبرداری مجدد که توزیع دادهها را تنظیم میکند یا استفاده از الگوریتمهای خاص که بر بهینهسازی معیارهایی مانند دقت و فراخوانی تمرکز دارند، با دادههای نامتوازن برخورد کنند.



دیدگاهتان را بنویسید